基本功能
在源代码基础上不需要改太多东西
- 首先对用户的url来处理,采用正则表达式 来处理输入的url r然后对结果进行反馈,来给用户更好的体验。

下面是更好的使用体验
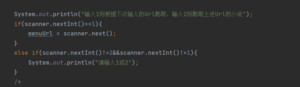
- 根据不同网站的href格式来处理url 。
测试时候笔趣阁
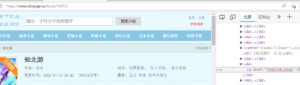
所以可以目录页url 直接加上 href的url 合并
而我们的作业
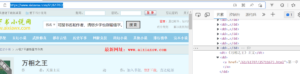
href里面含的更多 所以需要有针对性的进行修改
String STUrl = "https://www.aixiaxsw.com";
String subLink = a.attr("href");//获取每个章节的链接
chapter = Jsoup.connect(STUrl+subLink).get();//
//使用时候直接将大url加href的url就可以了- 至于count 或者cnt 的作用则是 排除最新章节的影响。

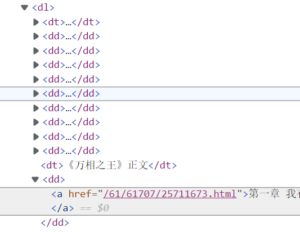
最终展示
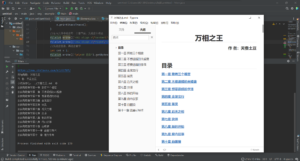
大纲那边是目录页折叠了,方便查看,所以每一章都是标题
拓展功能一
一、更换Maven下载源
为了方便演示,我重新下了个maven 。
- 首先官网下载Maven
Binary是可执行版本,已经编译好可以直接使用。
Source是源代码版本,需要自己编译成可执行软件才可使用。所以我下载的apache-maven-3.8.6-bin.zip
- 配置环境变量
- 首先右键此电脑–>属性–>高级系统设置–>环境变量
- 新建变量MAVEN_HOME = E:\Tools\Maven\apache-maven-3.8.6
- 编辑变量Path,添加变量值%MAVEN_HOME%\bin
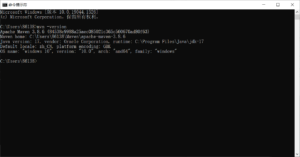
- 然后win+R运行cmd,输入mvn -version,如图所示则配置成功
- 配置本地仓库
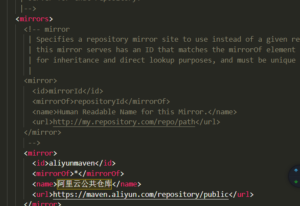
- 修改settins.xml (修改本地仓库以及更换镜像/下载源)

二、只打胖包
- 首先找到Project Structure
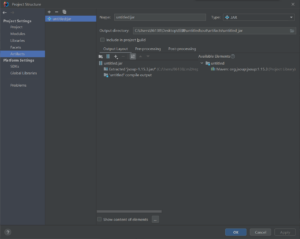
- 然后定入口函数(Main) 以及胖包的保存路径(默认当前目录下)
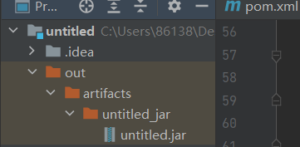
-
最上面 Build -- Build Artifacts
-
jar包目录下 使用cmd 命令行 运行jar包
二、保存小说更美观
markdown可以内嵌html语句
示例:
- 所以对于标题的居中我们可以使用(string 里面的 \ 使用 "\ 来)

- 每章标题的超链接以及标题(## 文字) 可以使用markdown语句
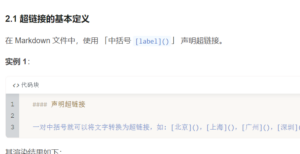

-
本来想用手动空格以及换行,但是发现爬取的.text()语句使用了空格后在Typora 中展示为代码格式。
最终选择使用.html()然后手动调节html的语句来达到首行缩进两个字符,通过string 替换 \n 来实现换行。

代码
package org.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws IOException {
/*
声明 一些常量 变量
*/
System.out.println("请输入爱下书小说的目录页地址(格式:https://www.aixiaxsw.com/105/105503/ : ");
String STUrl = "https://www.aixiaxsw.com";
Scanner scanner = new Scanner(System.in);
String menuUrl = scanner.nextLine();//默认目录页
while(!menuUrl.matches("https://www.aixiaxsw.com/[0-9]+/[0-9]+/")){
System.out.println("输入的URL不符合格式,请重新输入\n格式:https://www.aixiaxsw.com/105/105503/");
menuUrl = scanner.next();//
}
final String fileAddr = "./";//
System.out.println("输入1则根据下次输入的Url爬取,输入2则爬取上述Url的小说");
int op = scanner.nextInt();
if(op==1){
menuUrl = scanner.next();
}
else if(op!=2&&op!=1){
System.out.println("请输入1或2");
}
/*
访问目录页,获取小说名,章节名,章节链接。
*/
Document document =null;
try {
document = Jsoup.connect(menuUrl).get();
}catch (IOException e){
e.printStackTrace();
}
String title = document.body().selectFirst("h1").text();//小说名
String author = document.body().selectFirst("p").text();//作者名
System.out.println("开始爬取:"+title+"\n"+author);
Elements menu = document.body().select("dl dd");//选择父元素为dl 的dd元素
Elements as = menu.select("a[href]");
/*
新建文件 文件流
*/
System.out.println("小说将存在: "+fileAddr + title+".md 中");
File file = new File(fileAddr + title+".md");
OutputStream fileOut = null;
try{
fileOut = new FileOutputStream(file);
}catch (FileNotFoundException e){
e.printStackTrace();
}
//在向文件中输出每一个章节前,先输出小说名
fileOut.write(("<h1 align =\"center\">"+title+"</h1>\n\n").getBytes());
fileOut.write(("<h4 align =\"right\">"+author+"</h4>\n\n").getBytes());
//先输出目录,再输出章节
int cnt = 1;
fileOut.write(("\n\n## 目录").getBytes());
for(Element a : as){
if(cnt<=9){
cnt++;
continue;
}
String subLink = a.attr("href");//获取每个章节的链接
String chapterName = a.text();//章节名称
fileOut.write(("\n\n##### [" + chapterName +"]("+STUrl+subLink+")").getBytes());// []()附加超链接
}
/*
保存每个章节的正文到文件中,
*/
int count = 1;
for(Element a : as){
if(count<=9){
count++;
continue;
}
String subLink = a.attr("href");//获取每个章节的链接
String chapterName = a.text();//章节名称
System.out.println("当前爬取章节"+chapterName);
// System.out.println(STUrl+subLink);
Document chapter = null;
try{
chapter = Jsoup.connect(STUrl+subLink).get();//
//connect 访问链接
}catch (IOException e){
e.printStackTrace();
}
Element chapterContent = chapter.selectFirst("#content");//查找第一个这样的元素 ---正文
String MainContent = chapterContent.html().replaceAll("<br>","\n");
fileOut.write(("\n\n## "+chapterName+"\n\n" +" "+MainContent).getBytes());
// fileOut.write(("\n\n## [" + chapterName +"]("+STUrl+subLink+")" +"\n\n" +" "+MainContent).getBytes());
}
System.out.println("小说爬取成功!!");
fileOut.close();
}
}