爬虫作业
一.学习内容
1.学会使用简单的正则表达式,进行筛选,替换,从而达到自己想要的目的.
例:
Element chapterContent = chapter.selectFirst("#content");
// System.out.println(chapterContent.text().substring(28));
String text=chapterContent.text();
String content="笔趣阁 www.xbiquge.so,最快更新"+title+" !";
String REPLACE=" ";
Pattern p=Pattern.compile(content);
Matcher m=p.matcher(text);
text = m.replaceAll(REPLACE);2.用jsoup进行爬取自己想要的内容.
3.在代码中实际应用了md语法.
二.问题
在应对如识别格式不正确的问题上,仅用以下代码来识别前面协议部分.
String www="";
for(int i= 0;i<8;i++)
{
www=www+menuUrl.charAt(i);
}
System.out.println(www);
String b="https://" ;
if(!www.contentEquals(b))
{
System.out.println("您输入的地址格式不对,请重新运行程序.");
System.exit(0);
}
三.思考
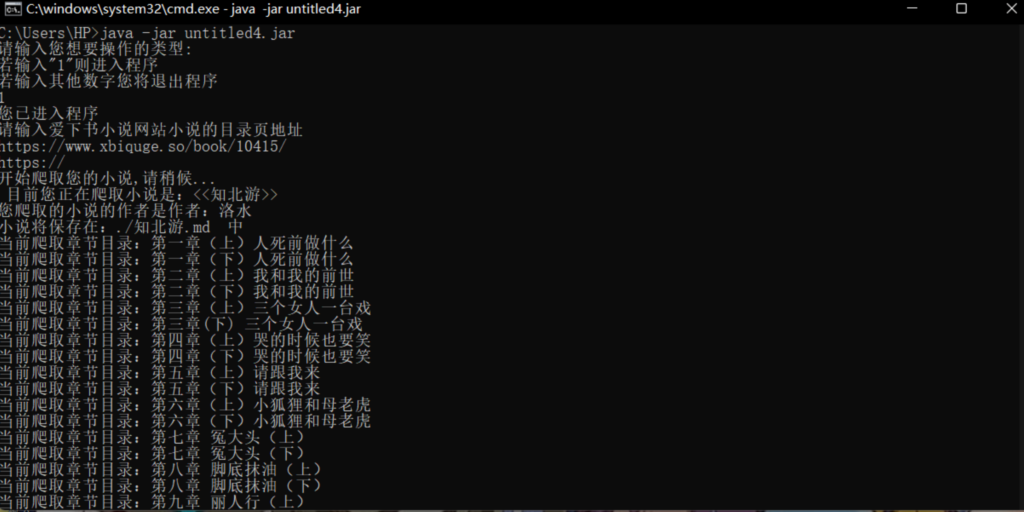
1.为了让用户使用方便,添加了一个进入系统,
System.out.println("请输入您想要操作的类型:");
System.out.println("若输入\"1\"则进入程序\n若输入其他数字您将退出程序");
int began= scanner.nextInt();
if(began==1) {
System.out.println("您已进入程序\n请输入爱下书小说网站小说的目录页地址");
menuUrl = scanner.next();
String www="";
for(int i= 0;i<8;i++)
{
www=www+menuUrl.charAt(i);
}
if(www!="https://")
{
System.out.println("您输入的地址格式不对,请重新运行程序.");
System.exit(0);
}可让用户进行操作自己想要操作的类型,进入或退出系统.
2.对于目录中可以链到具体小说用以下代码获取并获取出相应链接,并配合md进行操作.
String subLink = a.attr("href");
String chapterName = a.text();
System.out.println("当前爬取章节目录:"+chapterName);
String mainlink=menuUrl+subLink;
Document chapter = null;
try {
chapter = Jsoup.connect(menuUrl+subLink).timeout(10000).get();
} catch (IOException ewww) {
ewww.printStackTrace();
}
fileOut.write(("\n\n"+"##"+"["+chapterName+"]"+"("+mainlink+")").getBytes());3.已学习Maven,打胖瘦包.