前言:感动,至少我完成的很满意了/(ㄒoㄒ)/~~
我们首先看一下效果吧
运行后,我们根据提示输入1或者2及要爬取小说的网址
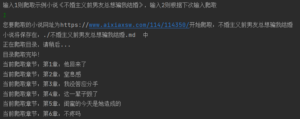
若有人看不见示例(我们不推荐这样的用户使用/(ㄒoㄒ)/,会自动补全网址):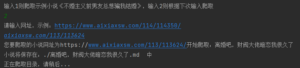
爬取完的小说会格式完美的以markdown的形式保存
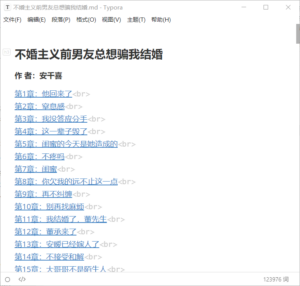

本次作业中遇到了很多问题,都成功找到了解决方法/★,°:.☆( ̄▽ ̄)/$:.°★
总结如下:
1.章节网址
起初我将示例网址直接换成了本次作业要求的小说网站的网址,发现总是出现如图所示的报错

后来发现问题出现在每章的网址上,这使得访问的网址总是404不存在。
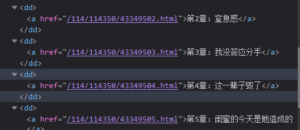


也就是说在本小说网站中,每章的网址并不如课上实例展示的为
menuUrl+subLink而应改为
"https://www.aixiaxsw.com"+subLink2.获取标题、作者
String title = document.body().selectFirst("h1").text();
String author = document.body().selectFirst("p").text();
fileOut.write(("### "+title+"\n\n").getBytes());
fileOut.write(("<b>"+author+"</b>"+"\n\n").getBytes());在这里给标题加了h3标题的格式,作者名字加粗了
3.获取目录
System.out.println("正在爬取目录,请稍后...");
int count1 = 1,num=1;
//循环操作每个章节
for (Element a : as) {
if (count1 <= 9) {
count1++;
continue;
}
String subLink = a.attr("href");
String chapterName = a.text();
Document chapter = null;
try {
chapter = Jsoup.connect("https://www.aixiaxsw.com"+subLink).get();
} catch (IOException ewww) {
ewww.printStackTrace();
}
fileOut.write(( "<a href="+"\""+"#"+num+"\">"+chapterName +"</a>"+"<br>").getBytes());
num++;
}
System.out.println("目录爬取完毕!");在爬取目录时加上了页面内跳转的功能
4.跳过最新章节爬取正文章节

我们会发现该小说网站会有9章的最新章节放在最前面,而他们都是在相同的html标签下,我们这里采用了一个小小的计数器。
for (Element a : as) {
if (count1 <= 9) {
count1++;
continue;
}跳过前9个章节
5.小说格式
这是做的较为粗糙的一个部分,按照上课讲的内容我们是以这种方式获取的正文
Elements chapterContent = chapter.select("#content");经过查询,我没找到在这基础上保存格式的方法,但经过观察,小说分段有原则,以。”为结尾即会分段,所以我们把这个问题简化为遇到这些分段并添加段前空格即可。
所以添加亿些些细节,我们得到了如下代码 ↓
Elements chapterContent = chapter.select("#content");
String str1=chapterContent.text().replace("。","。<br> ");
String str2=str1.replace("!","!<br> ");
String str3=str2.replace("\"","\"<br> ");
String Str=str3.replace("?","?<br> ");
fileOut.write(("\n\n" +"<b> "+chapterName + "</b>"+ "<p id=\""+num+"\">"+"<br>"+" "+Str+"</p>").getBytes());
num++;
同时在这段代码中也细节的将每章标题加粗了。
最后放代码↓
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.http.HttpHeaders;
import java.net.http.HttpRequest;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
import org.jsoup.safety.Cleaner;
public class Spider {
public static void main(String[] args) throws IOException {
//确定网址
String menuUrl = "https://www.aixiaxsw.com/114/114350/";//默认目录页
final String fileAddr = "./";
Scanner scanner = new Scanner(System.in);
System.out.println("输入1则爬取示例小说《不婚主义前男友总想骗我结婚》,输入2则根据下次输入爬取");
if(scanner.nextInt()==2) {
System.out.println("请输入网址,示例:https://www.aixiaxsw.com/114/114350/");
menuUrl = scanner.next();
boolean www=menuUrl.contains("www.");
if(!www){
menuUrl="www."+menuUrl;
}
boolean http=menuUrl.contains("https://");
if(!http){
menuUrl="https://"+menuUrl;
}
boolean a=menuUrl.endsWith("/");
if(!a){
menuUrl=menuUrl+"/";
}
}
System.out.print("您要爬取的小说网址为"+menuUrl);
// 获取文档对象
Document document = null;
try {
Connection con = Jsoup.connect(menuUrl).userAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36")
.timeout(30000); // 设置连接超时时间
Connection.Response response = con.execute();
if (response.statusCode() == 200) {
document = con.get();
} else {
System.out.println(response.statusCode());
return;
}
} catch (IOException e) {
e.printStackTrace();
}
String title = document.body().selectFirst("h1").text();
System.out.println("开始爬取:"+title);
String author = document.body().selectFirst("p").text();
Elements menu = document.body().select("div[id=list]").select("dl dd");
Elements as = menu.select("a[href]");
System.out.println("小说将保存在:"+fileAddr + title+".md 中");
File file = new File(fileAddr + title+".md");
OutputStream fileOut = null;
try {
fileOut = new FileOutputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
// 在向文件中输出每一章节前,先输出小说名和作者名
fileOut.write(("### "+title+"\n\n").getBytes());
fileOut.write(("<b>"+author+"</b>"+"\n\n").getBytes());
System.out.println("正在爬取目录,请稍后...");
int count1 = 1,num=1;
//循环操作每个章节
for (Element a : as) {
if (count1 <= 9) {
count1++;
continue;
}
String subLink = a.attr("href");
String chapterName = a.text();
Document chapter = null;
try {
chapter = Jsoup.connect("https://www.aixiaxsw.com"+subLink).get();
} catch (IOException ewww) {
ewww.printStackTrace();
}
fileOut.write(( "<a href="+"\""+"#"+num+"\">"+chapterName +"</a>"+"<br>").getBytes());
num++;
}
System.out.println("目录爬取完毕!");
int count = 1;
num=1;
//循环操作每个章节
for (Element a : as) {
if (count <= 9) {
count++;
continue;
}
String subLink = a.attr("href");
String chapterName = a.text();
System.out.println("当前爬取章节:"+chapterName);
Document chapter = null;
try {
chapter = Jsoup.connect("https://www.aixiaxsw.com"+subLink).get();
} catch (IOException ewww) {
ewww.printStackTrace();
}
Elements chapterContent = chapter.select("#content");
String str1=chapterContent.text().replace("。","。<br> ");
String str2=str1.replace("!","!<br> ");
String str3=str2.replace("\"","\"<br> ");
String Str=str3.replace("?","?<br> ");
fileOut.write(("\n\n" +"<b> "+chapterName + "</b>"+ "<p id=\""+num+"\">"+"<br>"+" "+Str+"</p>").getBytes());
num++;
}
System.out.println("小说爬取完成");
fileOut.close();
}
}
成就感拉满————————
注:拿《不婚主义前男友总想骗我结婚》当示例小说主要是因为它短!!与个人癖好没有任何关系!!
再注:我一开始爬的几千章的小说,Typora显示文件太大打不开,也没有很大吧呜呜呜