IO流之爬Bug
又是一个深夜,
头发要掉光光啦!?
嗯!这次博客的主题当然是爬虫!
maven学习
接上次培训,这一次培训正式开始用上了maven,故借此机会进一步学习。! 然而管中窥豹罢了,可恶
在这里就简单介绍一下我学到的关于maven的一些point和tips吧
经过这次写爬虫的作业,对maven的评价就是:爽!
咳咳,然而似乎在这样一个小型的项目上maven并没有展现出它的价值,但总之,也是很方便的啦当然,我想大家都已经感受到maven就很像一个工具,能帮助提升开发效率
obviously 它的优点不止于此从大的方面来看:maven简化了项目构建流程,并且给定了一套标准项目模型;
Maven对项目的目录结构、测试用例命名方式等内容都做了标准规定,使用 Maven 管理的项目须遵守这些规则。
例如此次爬虫,在项目文件目录之下有src,.idea,target,out等子目录,这些都是maven所标准化的POM.xml:
这是maven的基本组件,其中定义项目的基本信息,描述项目构建方式,声明依赖项
当maven执行一个任务,它会先读取POM文件获得所需配置信息,然后执行
POM中可设置的配置如下:
- 项目依赖
- 插件
- 目标
- 构建时的配置文件
- 版本
- 开发者
- 邮件列表
创建 POM 之前,首先要确定工程组(groupId),及其名称(artifactId)和版本,这些属性是项目的唯一标识
如下图: Super POM:
所有的POM都继承自一个父亲POM,它包含一些maven默认配置,在执行时maven使用effictive pom来执行,即调用父亲配置和本身配置
另外显然的但值得一提的是:实际开发过程中Maven 的 pom.xml 文件不需要自己编写,maven本身 提供了大量的原型(Archetype)插件来创建项目接下来就再写一点和这次作业相关度高一点的
Maven坐标:
首先我们需要了解maven构件,一般说来将maven中的依赖、插件以及项目构建的输出等内容称之为maven构件。在这一次爬虫中我们使用到了jsoup依赖包(也就是一个构件),我们通过在POM文件中导入依赖的方式使用,而这就用到了所谓Maven坐标。
maven 坐标包括 groupId、artifactId、version、packaging 等元素;而maven构件来自于网站,通过maven坐标我们能定位构件并导入,这就是maven坐标存在的意义。
maven强制要求所有构件都需要有自己的一个maven坐标;packaging元素可有可无Maven依赖:
如前所述,我们使用maven依赖需要以maven坐标为前提
在maven项目中声明一个maven依赖时,一般只需在POM中配置其坐标信息(如下图),maven自动导入该依赖到项目
获取依赖坐标:大部分依赖的 Maven 坐标都能在 https://mvnrepository.com/ 中获取嗯!maven就写到这里
(实际上开发经验不足,根本写不出什么东西来!!!)

爬Bug
下面就进入正题,开始爬!
产品介绍:
功能:
1.程序运行之后用户根据日志信息进行操作;输入1爬取爱下属小说网默认小说,输入爱下书小说网某一小说目录页url则爬取该小说,同时若用户输入不合法日志信息将提示是否重新输入或者退出程序,当用户输入网站缺少传输协议的时候,为用户加上https:// 传输协议
此处原本是应该实现抓取用户输入网址是否含有"www.aixiaxsw.com/数字串/数字串",如果有就进行自动补全,没有则返回输入循环的功能,但是在处理完一些输入流的bug之后没有意识到还需要对前面的交互进行改进就提交了,所以下次一定!
2.用户输入成功之后,程序将开始爬取指定小说。小说将保存在程序同级目录之下以小说名为name的文件夹中,其中catalog为作品信息文件(包含书名,作者名,目录),目录包含章节跳转,其余为章节文件,均以markdow格式保存在.md文件中代码实现:
交互:
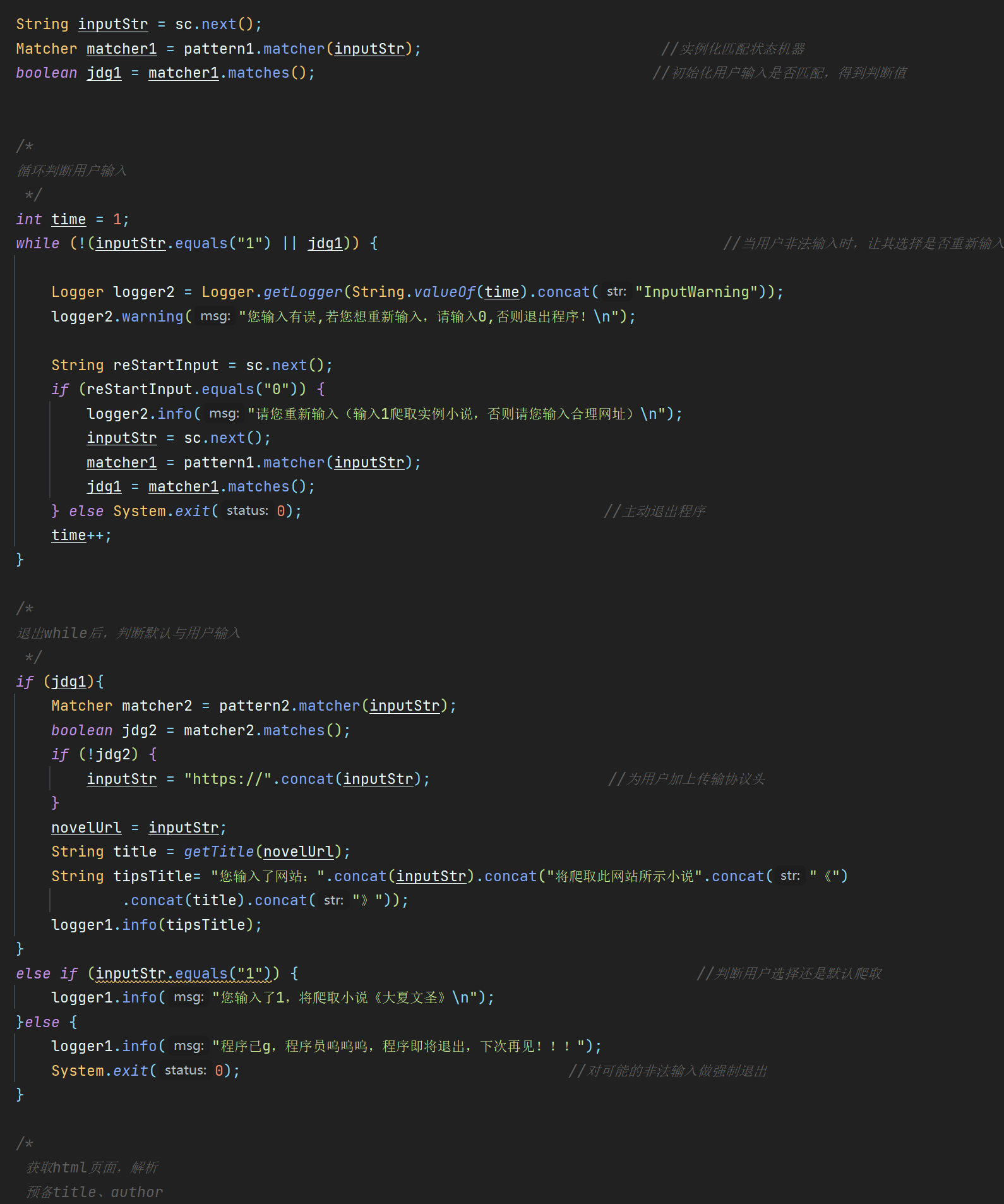
在整个代码中与用户交互的实现都是通过了一个日志API-java.util.logging包,其实在这样的代码中使用System.out.println也没有什么不便之处与用户交互使用了一个while循环:理论上用户在输入错误之后可以无限选择再次输入或者选择中途退出程序;提交的代码在此处没有使用一个int计数控制while在一定次数之后强制退出,是本应该实现的
对于用户输入的字符串判断使用正则表达结合pattern和macher类得到对应布尔值进行条件判断,此处的不足便是在产品功能已经提及到的没有实现提取字符串自动补全的操作,仅仅判断了是否缺失整个传输协议头
在输入判断语句if的最后加上了一句else System.exit,防止出现逃出if语句的输入的情况
代码如下:
好吧还是插入初始化变量的代码:根据输入获得小说的目录页html文档:
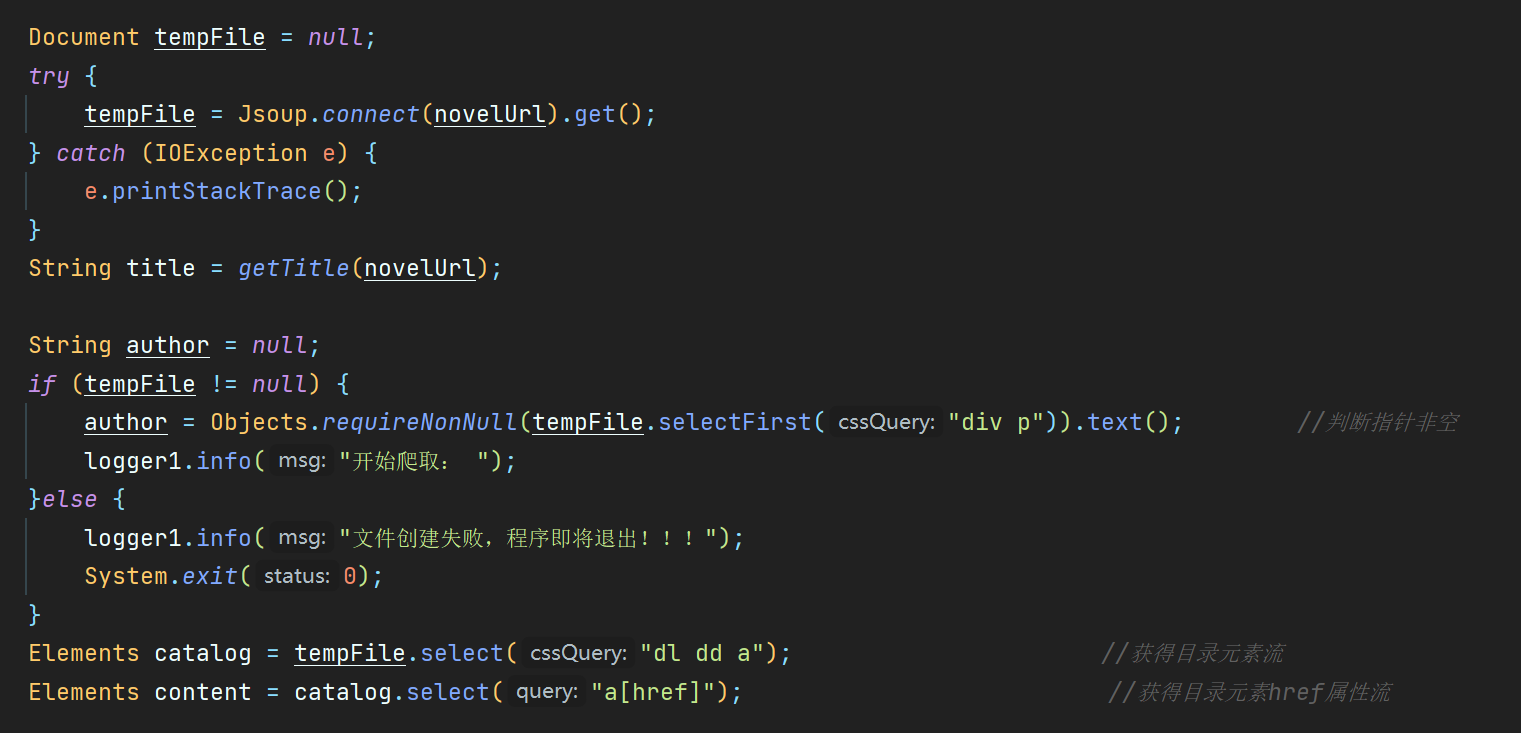
使用导入的jsoup包提供的connect.get()方法解析给定url的html页面
得到解析文档tempfile之后就可以使用css选择器提取作品名,作者名以及目录信息及其href信息作为elemen流以供之后使用;如果`tempfile不存在程序将退出
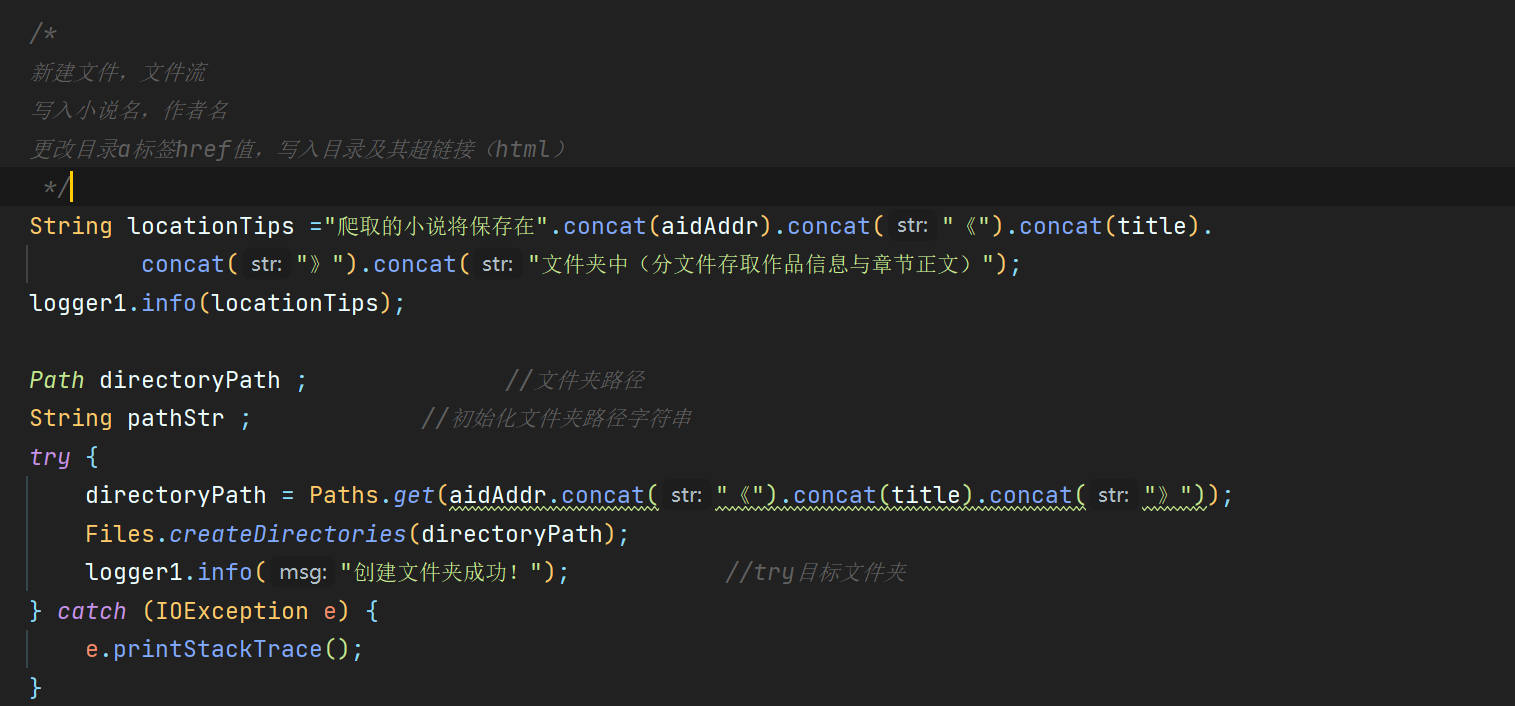
代码如下:新建文件夹:
创建文件夹的时候使用了java的NIO,目的是为了使得文件夹建立不成功时的异常抛出更加详细,其后的file建立也是如此(用了一个path想试一试,似乎path的输入与输出有一点不一样,还不是很确定)在这里也包裹了一个try-catch语句抛出异常
代码如下:
新建一个catalog.md文档存放基本信息(包含目录):
利用file类新建一个文件,然后初始化一个Outputstream novelOut,之后用到novelOut时更改其指向位置就可以向新建的文件中进行写入
代码如下:写入进本信息与目录:
基本信息写入直接使用.write方法就可以,处理目录写入时需要考虑到网页布局,由于该网站的最新章节栏都是九个章节,所以使用一个int计数continue就可以跳过;**这里应该使用选择器选择第二个dl标签之后的dd标签或者删除此前的标签,但是一直没有找到方法!!!wotaicaila我就是憨憨
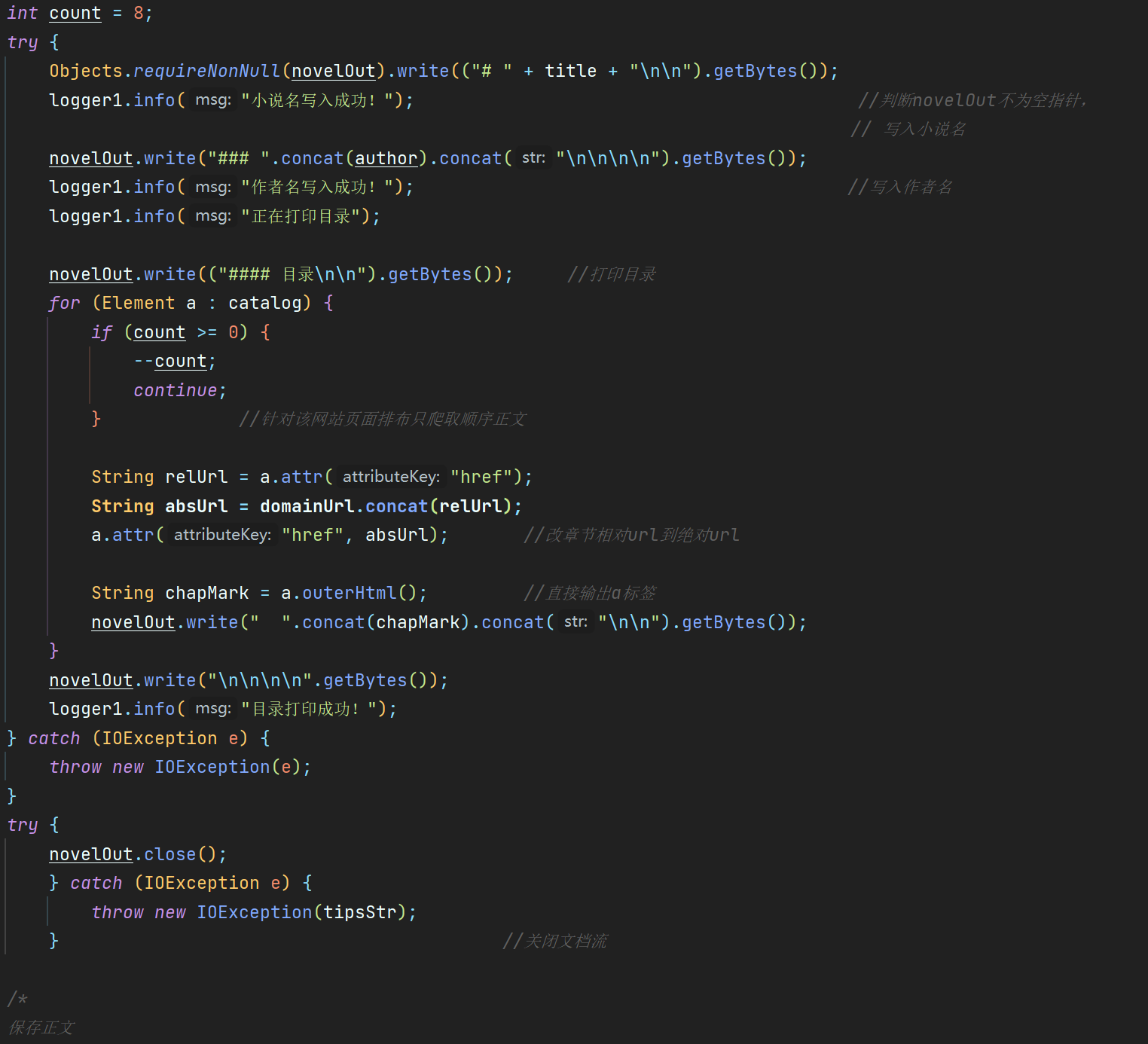
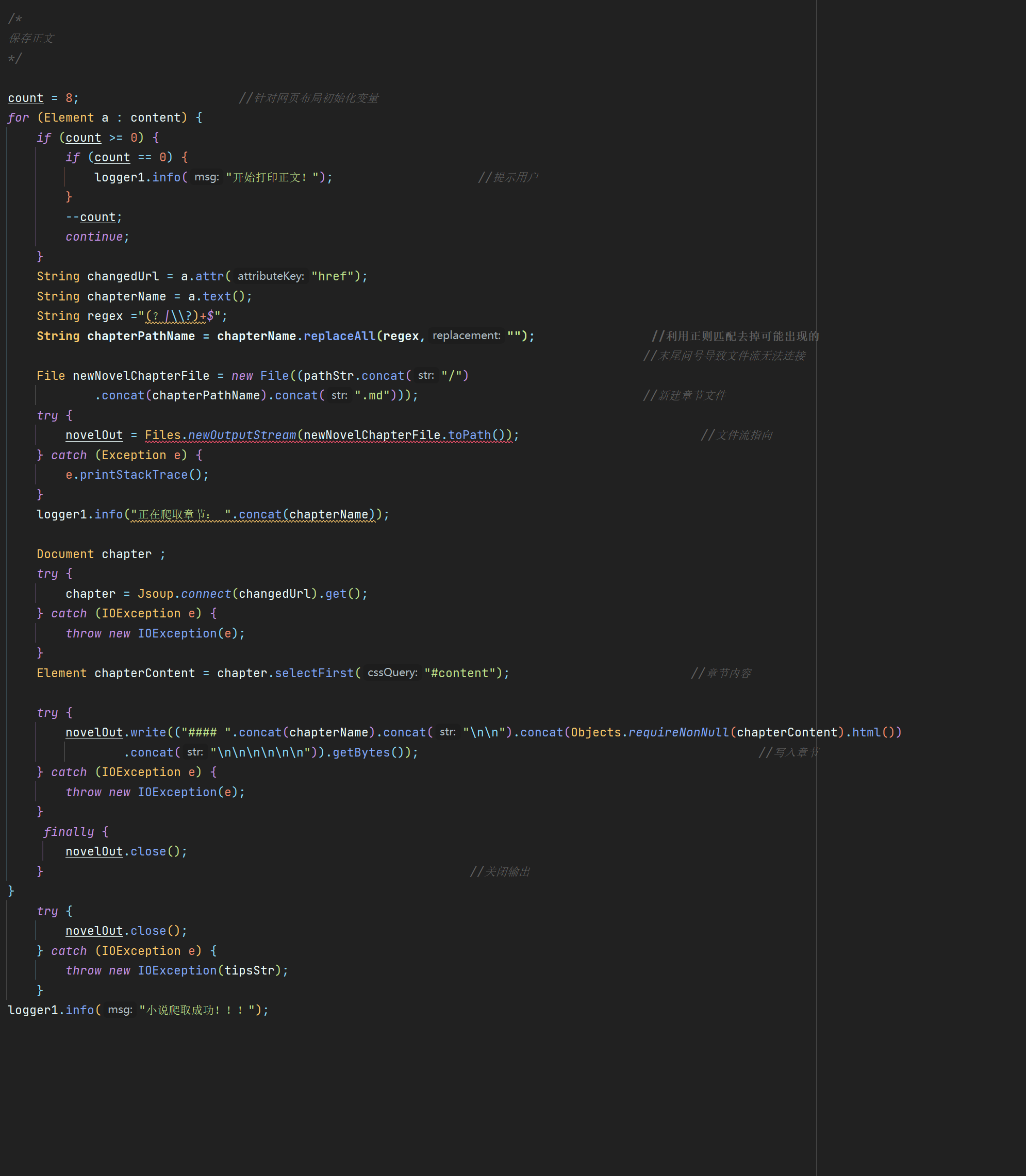
代码如下:打印正文:
和打印目录一样,大同小异,但是这里在测试过程中出现了一个小bug,在爬取一些章节名末尾带有问号的时候,new file和Outputstream无法连接或者单纯就是文件无法创建
这里我并没有找到具体的错误,但是使用正则表达replaceAll替换掉问号之后程序能继续爬取,所以猜测可能是以问号结尾或者是问号编码紊乱导致Outputstream不能连接的问题
在输入输出过程中值得一提的是要记得关闭输出流,防止溢出
代码如下:

程序就到此为止,看了看我的头发,嗯!!还能再战
附上全部代码:
~~
package training;
import java.util.Objects;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.logging.Logger;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.file.Path;
import java.io.*;
import java.util.Scanner;
public class Bug {
public static String getTitle(String url){
Document file ;
String title = null;
try {
file =Jsoup.connect(url).get();
title = Objects.requireNonNull(file.selectFirst("h1")).text();
}catch (IOException e) {
e.printStackTrace();
}
return title;
}
public static void main(String[] args) throws Exception {
/*准备爬取
预备声明
*/
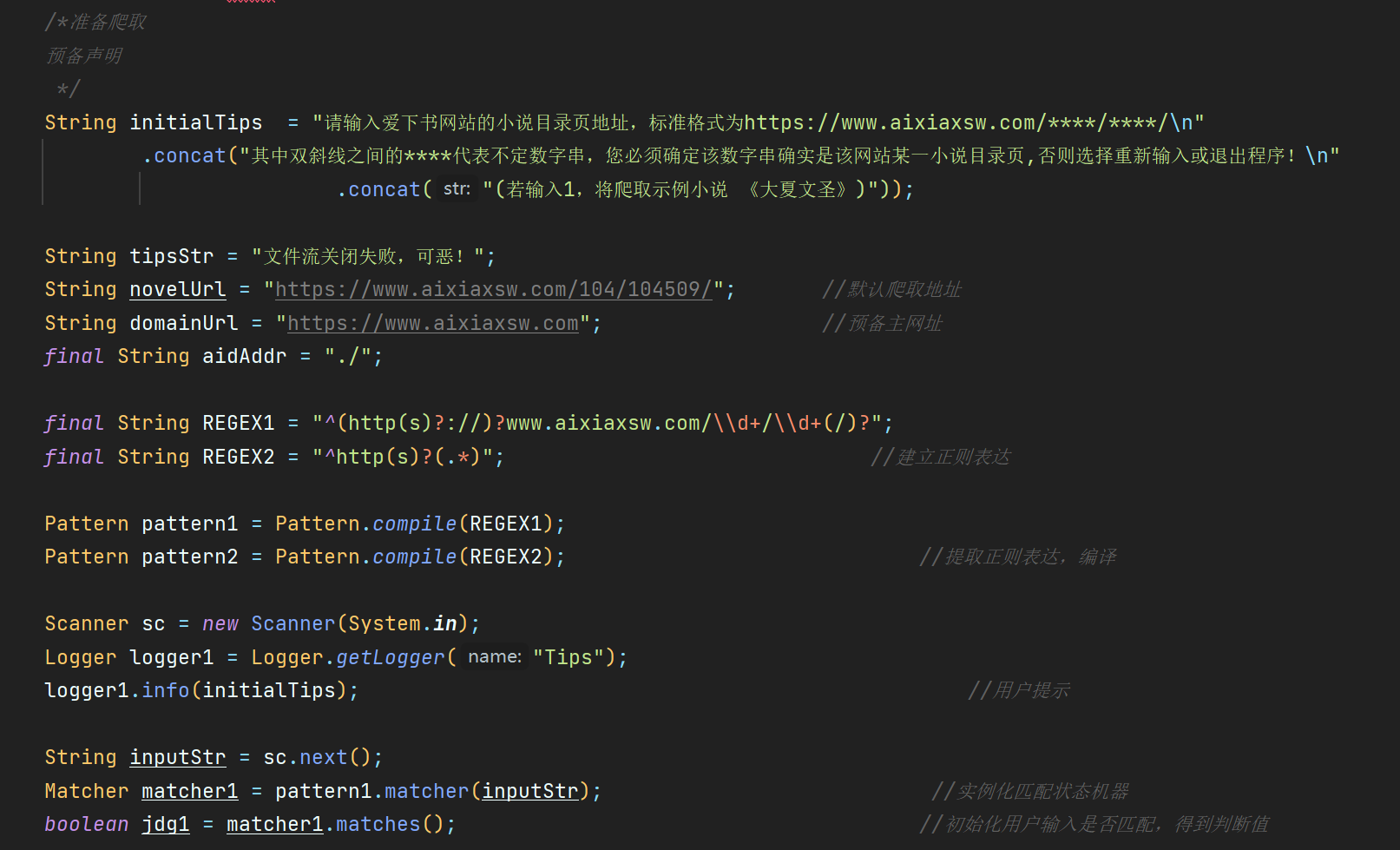
String initialTips = "请输入爱下书网站的小说目录页地址,标准格式为https://www.aixiaxsw.com/****/****/\n"
.concat("其中双斜线之间的****代表不定数字串,您必须确定该数字串确实是该网站某一小说目录页,否则选择重新输入或退出程序!\n"
.concat("(若输入1,将爬取示例小说 《大夏文圣》)"));
String tipsStr = "文件流关闭失败,可恶!";
String novelUrl = "https://www.aixiaxsw.com/104/104509/"; //默认爬取地址
String domainUrl = "https://www.aixiaxsw.com"; //预备主网址
final String aidAddr = "./";
final String REGEX1 = "^(http(s)?://)?www.aixiaxsw.com/\\d+/\\d+(/)?";
final String REGEX2 = "^http(s)?(.*)"; //建立正则表达
Pattern pattern1 = Pattern.compile(REGEX1);
Pattern pattern2 = Pattern.compile(REGEX2); //提取正则表达,编译
Scanner sc = new Scanner(System.in);
Logger logger1 = Logger.getLogger("Tips");
logger1.info(initialTips); //用户提示
String inputStr = sc.next();
Matcher matcher1 = pattern1.matcher(inputStr); //实例化匹配状态机器
boolean jdg1 = matcher1.matches(); //初始化用户输入是否匹配,得到判断值
/*
循环判断用户输入
*/
int time = 1;
while (!(inputStr.equals("1") || jdg1)) { //当用户非法输入时,让其选择是否重新输入
Logger logger2 = Logger.getLogger(String.valueOf(time).concat("InputWarning"));
logger2.warning("您输入有误,若您想重新输入,请输入0,否则退出程序!\n");
String reStartInput = sc.next();
if (reStartInput.equals("0")) {
logger2.info("请您重新输入(输入1爬取实例小说,否则请您输入合理网址)\n");
inputStr = sc.next();
matcher1 = pattern1.matcher(inputStr);
jdg1 = matcher1.matches();
} else System.exit(0); //主动退出程序
time++;
}
/*
退出while后,判断默认与用户输入
*/
if (jdg1){
Matcher matcher2 = pattern2.matcher(inputStr);
boolean jdg2 = matcher2.matches();
if (!jdg2) {
inputStr = "https://".concat(inputStr); //为用户加上传输协议头
}
novelUrl = inputStr;
String title = getTitle(novelUrl);
String tipsTitle= "您输入了网站:".concat(inputStr).concat("将爬取此网站所示小说".concat("《")
.concat(title).concat("》"));
logger1.info(tipsTitle);
}
else if (inputStr.equals("1")) { //判断用户选择还是默认爬取
logger1.info("您输入了1,将爬取小说《大夏文圣》\n");
}else {
logger1.info("程序已g,程序员呜呜呜,程序即将退出,下次再见!!!");
System.exit(0); //对可能的非法输入做强制退出
}
/*
获取html页面,解析
预备title、author
准备元素流
*/
Document tempFile = null;
try {
tempFile = Jsoup.connect(novelUrl).get();
} catch (IOException e) {
e.printStackTrace();
}
String title = getTitle(novelUrl);
String author = null;
if (tempFile != null) {
author = Objects.requireNonNull(tempFile.selectFirst("div p")).text(); //判断指针非空
logger1.info("开始爬取: ");
}else {
logger1.info("文件创建失败,程序即将退出!!!");
System.exit(0);
}
Elements catalog = tempFile.select("dl dd a"); //获得目录元素流
Elements content = catalog.select("a[href]"); //获得目录元素href属性流
/*
新建文件,文件流
写入小说名,作者名
更改目录a标签href值,写入目录及其超链接(html)
*/
String locationTips ="爬取的小说将保存在".concat(aidAddr).concat("《").concat(title).
concat("》").concat("文件夹中(分文件存取作品信息与章节正文)");
logger1.info(locationTips);
Path directoryPath ; //文件夹路径
String pathStr ; //初始化文件夹路径字符串
try {
directoryPath = Paths.get(aidAddr.concat("《").concat(title).concat("》"));
Files.createDirectories(directoryPath);
logger1.info("创建文件夹成功!"); //try目标文件夹
} catch (IOException e) {
e.printStackTrace();
}
pathStr = aidAddr.concat("《").concat(title).concat("》").concat("/");
File newNovelBasicIfm = new File((pathStr).concat("/").concat("catalog.md"));//目录文件创建
OutputStream novelOut= null ; //文件流
try {
novelOut = Files.newOutputStream(newNovelBasicIfm.toPath()); //文件流指向
} catch (Exception e) {
e.printStackTrace();
}
int count = 8;
try {
Objects.requireNonNull(novelOut).write(("# " + title + "\n\n").getBytes());
logger1.info("小说名写入成功!"); //判断novelOut不为空指针,
// 写入小说名
novelOut.write("### ".concat(author).concat("\n\n\n\n").getBytes());
logger1.info("作者名写入成功!"); //写入作者名
logger1.info("正在打印目录");
novelOut.write(("#### 目录\n\n").getBytes()); //打印目录
for (Element a : catalog) {
if (count >= 0) {
--count;
continue;
} //针对该网站页面排布只爬取顺序正文
String relUrl = a.attr("href");
String absUrl = domainUrl.concat(relUrl);
a.attr("href", absUrl); //改章节相对url到绝对url
String chapMark = a.outerHtml(); //直接输出a标签
novelOut.write(" ".concat(chapMark).concat("\n\n").getBytes());
}
novelOut.write("\n\n\n\n".getBytes());
logger1.info("目录打印成功!");
} catch (IOException e) {
throw new IOException(e);
}
try {
novelOut.close();
} catch (IOException e) {
throw new IOException(tipsStr);
} //关闭文档流
/*
保存正文
*/
count = 8; //针对网页布局初始化变量
for (Element a : content) {
if (count >= 0) {
if (count == 0) {
logger1.info("开始打印正文!"); //提示用户
}
--count;
continue;
}
String changedUrl = a.attr("href");
String chapterName = a.text();
String regex ="(?|\\?)+$";
String chapterPathName = chapterName.replaceAll(regex,""); //利用正则匹配去掉可能出现的
//末尾问号导致文件流无法连接
File newNovelChapterFile = new File((pathStr.concat("/")
.concat(chapterPathName).concat(".md"))); //新建章节文件
try {
novelOut = Files.newOutputStream(newNovelChapterFile.toPath()); //文件流指向
} catch (Exception e) {
e.printStackTrace();
}
logger1.info("正在爬取章节: ".concat(chapterName));
Document chapter ;
try {
chapter = Jsoup.connect(changedUrl).get();
} catch (IOException e) {
throw new IOException(e);
}
Element chapterContent = chapter.selectFirst("#content"); //章节内容
try {
novelOut.write(("#### ".concat(chapterName).concat("\n\n").concat(Objects.requireNonNull(chapterContent).html())
.concat("\n\n\n\n\n\n")).getBytes()); //写入章节
} catch (IOException e) {
throw new IOException(e);
}
finally {
novelOut.close();
} //关闭输出
}
try {
novelOut.close();
} catch (IOException e) {
throw new IOException(tipsStr);
}
logger1.info("小说爬取成功!!!");
}
}